Warning
The election has now come and gone, and the thing I said definitely wouldn’t happen – Labour winning fewer seats than they won in 1997 – has in fact happened. It seems that the reasons for our failure were connected to the second failure mode – a failure to get the overall vote shares right. The fact that Labour achieved such a large number of seats on such a low vote share suggests that they were efficient and that swing away from the Conservatives was proportional rather than uniform.
Note
Since this was written, there have been two delayed data drops. All fieldwork was conducted before polls opened. An update of Wednesday evening predicting Labour on 475 can be found here; an update of Thursday which predicts Labour of 470 can be found here. These last-minute updates are regrettable, but these models take a long time to run, and as a result it is not always possible for all the scheduled data to come in. There have been no code changes between these updates, just a couple of hundred new data points and some longer runs.
Yesterday Survation published an update from their MRP model, a model with which I have been closely involved.
The model predicts a Labour seat tally of 484, on a Labour vote share of 42%. The Conservatives are predicted to win 64 seats, on a vote share of 23%.
The forecast – and this close to the election we can probably dispense with the distinction between forecasting and nowcasting – has been roundly described as “punchy”.
Some might even describe it as “courageous”, but more in the Yes Minister sense of the word than implying any particular virtue on our part.
Because the forecast is “punchy”, I thought it might be helpful to discuss the main two failure modes of an MRP forecast:
- First, we might have got the mapping between national vote share and seats wrong. Labour might win as many votes as we think, they’ll just be in different places, leading to a lower seat haul.
- Second, we might have got the vote shares wrong: Labour might win fewer votes than we think, and/or the Conservatives more.
I’m going to consider these two failure modes in order to explain why I felt confident about the claim that Labour are almost certain to win more seats than they did in 1997. This claim is particularly important to me because I don’t want to be associated (again) with ruling out something that then went on to happen, as I did in 2015 when I said there was almost no chance of a Conservative majority.
I’m going to start with the mapping between national and local. We model how respondents say they’ll vote, and then make predictions at the local level. We do this because we believe there’s no simpler way of doing – no axiomatic rule that allows us to say that a party with such and such share of the vote should win x or y percent in this area. However, it is helpful to consider some simple rules as reference points, and evaluate our forecast in that light.
Historical UK and comparative reference points
One reference point is to look at past historical elections where there was a large gap between the first and second-placed, and first and third placed parties, and see what share of seats the first-placed party won. I focus on the gap between first and second because under first past the post it’s not enough to do well in an absolute sense: you also have to be ahead of your opponent. A vote share of 48% can win you almost all of the seats if your nearest opponent is on 24%; it can lose you almost all of the seats if your nearest opponent is on 52%.
In post-war UK electoral history, the two elections with a big lead are the elections of 1997 and 1983. In 1997, Labour polled 12.8 percentage points ahead of the Conservatives in Great Britain, and won 418 seats, albeit in a slightly larger House of Commons of 659. At present, Labour’s share of the vote is lower than it was in 1997, but its lead over the Conservative party is greater. If the Labour lead is greater than 1997, then maybe the Labour seat count will be bigger too.
In 1983, the Conservatives polled almost sixteen percentage points ahead of Labour in Great Britain, and won 397 seats. At present, Labour’s share of the vote is lower than the Conservative share was in 1983, but their lead is once again greater. This example is less favourable to Labour, in that it implies that you can rack up a sixteen point lead and still not break four hundred, but sixteen points is less than what we see at present.
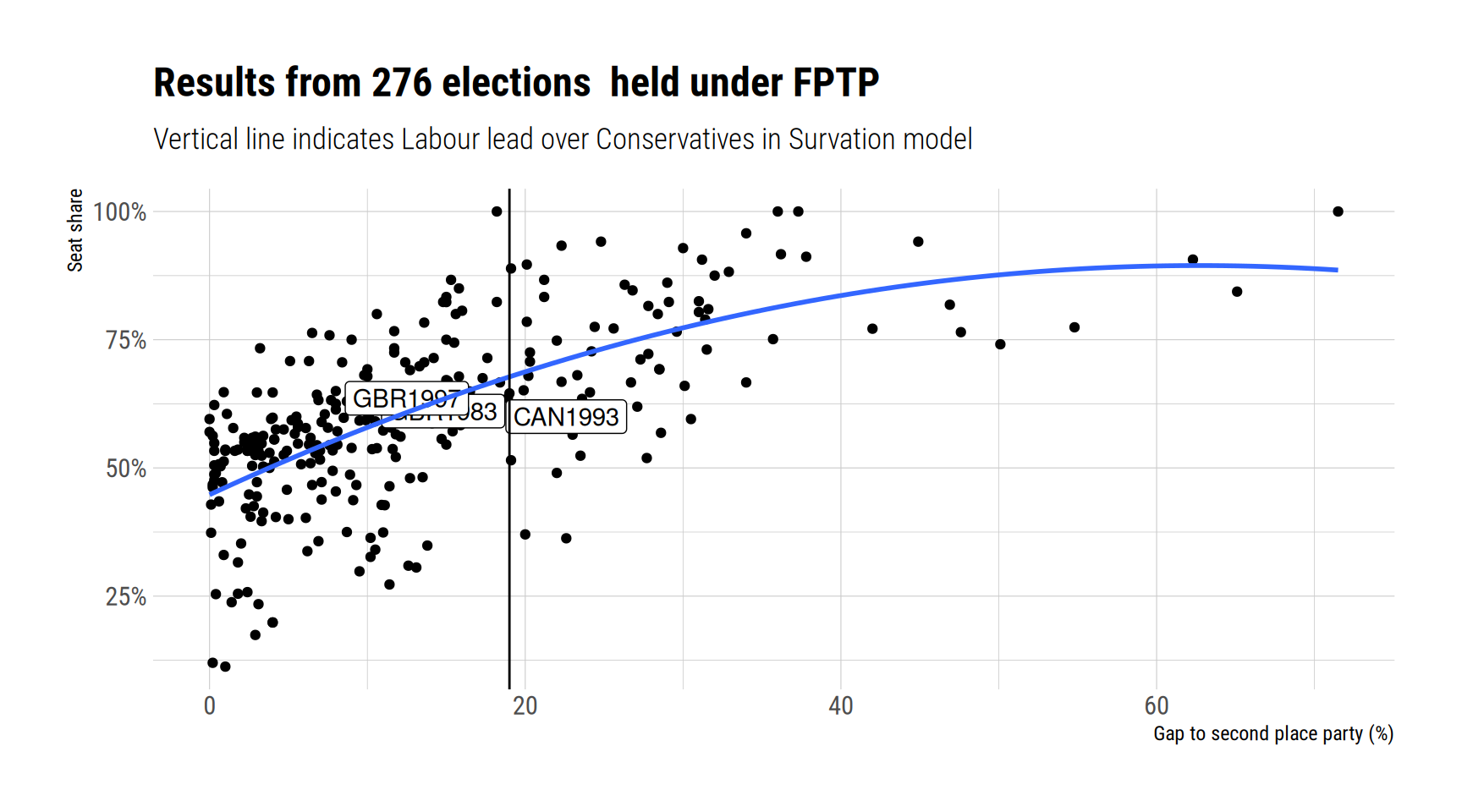
More generally we can look at all post-war democratic elections and examine those elections which were held under first-past-the-post, and plot the gap to second place against the leading party’s seat share.
I’ve plotted that using data from ElectionsGlobal combined with information from Democratic Electoral Systems in order to restrict my analysis to elections held under first past the post. I’ve also added a polynomial trend line to show what we might expect at different leads, if we knew nothing other than the gap between the first- and second-placed party. The trend line fits the two UK elections just mentioned quite well.
The suggestion from the trend line is that if you have a lead of around 19%, you might expect to win 68% of seats, or (0.68 * 650) = 442 seats.
Comparative evidence therefore suggests that if you knew nothing about the election except the Labour lead over the Conservatives and the fact that the election is being contested under first-past-the-post, then you would predict a very large seat share. This comparative evidence is in line with two UK historical examples, which would predict that the Labour seat share in 2024 should be greater than the Labour seat share in 1997, or the Conservative seat share in 1983, because the Labour lead is bigger than either party’s lead was in those two elections.
Uniform and proportional swing
At this point it might reasonably be objected that we do in fact know more than simply the Labour lead over the Conservatives and the fact that the election is being held under first-past-the-post. We know past support for each party in each seat from notional election results. This can help us predict seat counts under an assumption of uniform national swing, such that if Labour is up so many percentage points, we can add that to their performance last time, and by repeating this for all parties, calculate who is in the lead in each seat.
John Curtice has helpfully calculated the seat count under uniform national swing using an average of vote shares from different MRP models. Under UNS, you get a Labour total of 370, with the SNP on 34. This calculation precedes the most recent Survation update.
Uniform national swing does have a tremendous record in predicting seat outcomes. It is very useful, but it does have some limitations. The main limitation is that it can create negative values where a party’s national vote share goes down by more than it previously won in a seat. (The converse, where adding an increase to a party’s national share would take its local share to greater than 100%, is rarely if ever seen). Since parties cannot win negative votes, then any national change which implies negative votes in some places means that the change must be less than uniform (i.e., less steep) in some places, and correspondingly more than uniform (i.e., steeper) in some other places. Sometimes the label used more this type of swing is proportional, since the amount of swing is proportional to how well the party did previously.
Usually this limitation of uniform national swing is not a serious limitation, and is very rarely a serious problem for one of the two largest parties. However, the likely change in the Conservative vote is so large than applying uniform national swing creates some problems. If we suppose a change in the Conservative vote share of twenty points, then there are almost ninety seats where uniform national swing would create negative Conservative vote share. If we sum up the negative votes predicted, that’s almost 350,000 extra votes which have to come from other seats, or roughly one percent of the national vote share. This means that the Conservatives would need to lose one percentage point more than their nation-wide loss in all the other seats just to make the sums add up. If we suppose that the Conservative vote never reaches exactly zero, but falls to one or two percent, then the figures become even greater.
Uniform national swing will therefore be placed under severe pressure in this election, and there is no golden rule saying that when UNS is under pressure, it will emerge triumphant. Steve Fisher and Jake Dibden have helpfully analysed cases where parties have suffered large national swings, and examined the proportionality of their swing in these cases. The conclusion is that proportional swing can well happen when there are large national swings.
What I take from these two analyses is that uniform national swing sets a plausible lower bound on the Labour seat tally, and that we should therefore expect a figure greater than 370. “How much greater” is, of course, a matter of further analysis, and the point of MRP modelling is to take the analysis to the level of the voter and make post-stratified predictions. Our election models in 2017 and 2019, conducted for private clients in the financial sector, were reasonably accurate in terms of the headline seat counts, and for that reason we opted to retain the model we had used for 2019, without making any adjustments to account for attenuation.
Getting the headline figures wrong
The discussion of comparative reference points and models of swing suggest that even if our mapping between national vote share and seat level outcomes is wrong in the specific sense of being too favourable to Labour, then we would still expect a very big Labour figure based on Labour’s lead over the Conservative party and its change in the share of the vote since last time.
The second failure mode of MRP models is that they get the national shares wrong. Because the national shares are just aggregates of what we predict at local level, if we get the national shares wrong it means we’ve also gotten the local results wrong.
We might get it wrong because MRP relies on polling, and because the errors in modern polling are not the kinds of errors that result from simple random sampling. Opinion pollsters rely on people who opt-in to internet panels or who pick up the phone to queries from polling companies. These people are different from the general population. Although we can adjust for some of these differences – and in particular, we adjust for age, sex, highest level of qualifications, past vote, and constituency – we cannot adjust for characteristics for which we have no national reference point, like “political interest” or “agreeableness”, neither of which feature on the Census (though maybe they should).
It is therefore possible that although the samples used for MRP are very large, they could be very wrong. If there is a polling miss of the same direction and magnitude as there was in 1992 or 2015, our seat forecasts would be very wrong. Most big polling misses are collective misses, but here there is a canary in the mine: polls like the most recent poll from Verian, a company which I greatly respect, suggest a very different picture, with a 15 point Labour lead over the Conservatives (36 over 21).
The question to ask, therefore, is: could the polls be wrong? This question was extensively discussed at a recent British Polling Council event on the 5th June. The general conclusion from that event was that there was very little evidence from Westminster by-elections or local elections to suggest that they are very wrong. In particular, I took heart from one random probability sample by Verian, which at the time was giving very similar national vote shares to our MRP model at the time. Random probability samples, which involve drawing people at random from a list and repeatedly going back to them until they answer, are an expensive gold standard.
My view is therefore that whilst error in the overall vote share is the single greatest point of failure in our model, there is not much evidence to suggest that failure is likely, or more likely than normal. The pattern of failure would have to be quite specific, and (given the random probability sample I mentioned earlier) would likely have to have emerged during the course of the election, either because of opinion change or because of a compositional change which emerges when you weight by turnout likelihood.
Vibes check
One source of information which I think can be discarded are reports by Labour canvassers who say that they are not detecting the same kinds of enthusiasm which they detected in 1997, and that therefore Labour cannot be on course for a similarly large victory. “Enthusiasm” in some absolute sense does not matter in elections. Our MRP model is not forecasting that Labour will win more votes than they did in 1997, and might for that reason be more popular or the subject of greater enthusiasm. Indeed, we’re only just confident that they’ll poll a greater vote share than they did in 2017. What matters is not enthusiasm for Labour, but a general weariness of the Conservatives. That sentiment does not seem to be in short supply.
Conclusions
This is the kind of forecast that you want if you don’t want to see herding: people who are following an existing model, who trust in the process, and don’t make adjustments to reflect an external view of what seems most likely. Unfortunately it is also the kind of forecast that means that on Friday morning there is a chance that we will have egg on our faces. Right now I am dwelling more on that chance that the chance we will look like seers.